Designing Disaster Recovery Strategy on AWS (RTO & RPO Explained)

ကျွန်တော်တို့ production system တစ်ခု run နေတဲ့အချိန်မှာ server failure, database corruption နဲ့ region outage ဖြစ်တာမျိုးတွေကို ဘယ်လိုမြန်မြန် recover လုပ်နိုင်မလဲ ဆိုတာ တွေးတတ်ဖို့ ရှိချင်ပါတယ်။ ဒီနေရာမှာ Disaster Recovery strategy က အရေးပါလာပါပြီ။
အများစုက real world project တွေမှာ data backup လုပ်ထားတာက safe ဖြစ်တယ်လို့ ယူဆကြတယ်။ ဥပမာ database snapshot ယူထားတာ၊ file တွေကို S3 ထဲ သိမ်းထားတာမျိုးပေါ့။ ဒါပေမယ့် issue တစ်ခု ဖြစ်လာတဲ့အခါ backup တစ်ခုဘဲ လုပ်ထားရင် restore လုပ်ဖို့ အချိန်ကြာသွားတဲ့အခါ ကိုယ် run နေတဲ့ business ကို အကြီးအကျယ် impact ဖြစ်နိုင်ပါတယ်။ ဒီလို problem တွေကို စဉ်းစားတဲ့အခါ RTO (Recovery Time Objective) နဲ့ RPO (Recovery Point Objective) ဆိုတဲ့ concept နှစ်ခုကို သုံးကြပါတယ်။
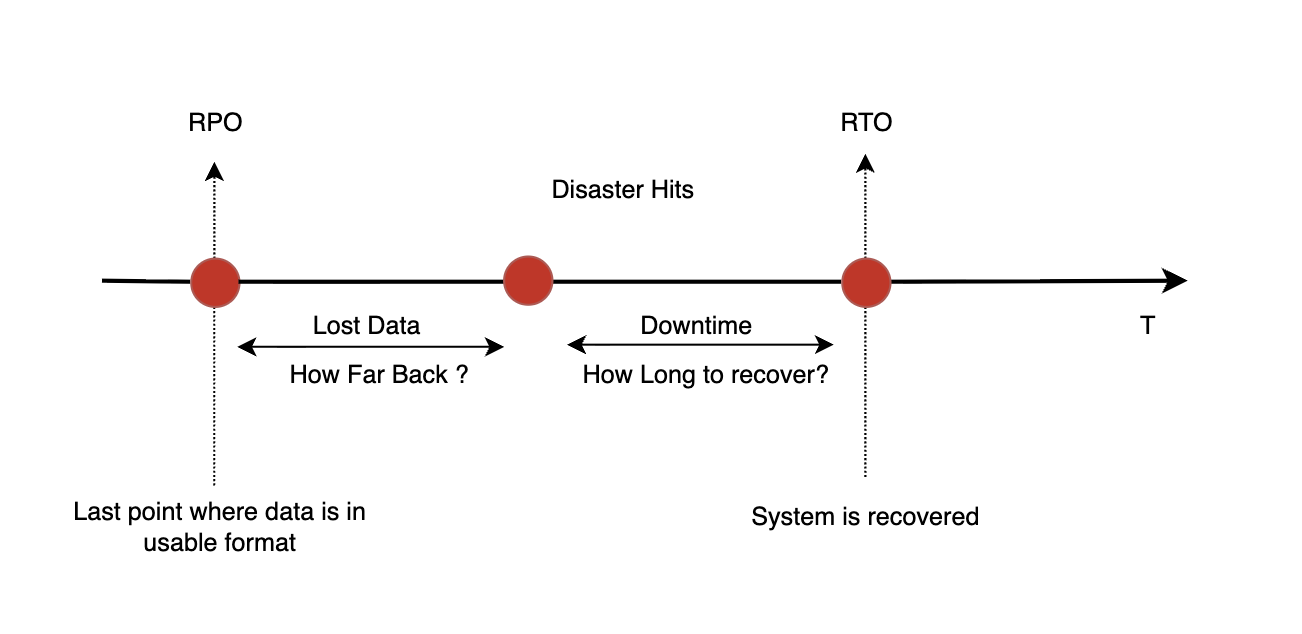
RTO ဆိုတာ system ပြန် run ဖို့ အချိန် ဘယ်လောက်အထိ allow လုပ်နိုင်လဲ ဆိုတာပါ။ RPO ဆိုတာ data loss ကို ဘယ်လောက်ထိ လက်ခံနိုင်လဲ ဆိုတာပါ။ ဥပမာ system တစ်ခုမှာ RTO က 1 hour လို့ သတ်မှတ်ထားရင် incident ဖြစ်ပြီး 1 hour အတွင်း system ပြန် run နိုင်ရပါမယ်။ RPO က 10 minutes ဆိုရင် data loss 10 minutes ထက် မကျော်သင့်ပါဘူး။
ပထမဆုံး approach က backup-based recovery ပါ။ AWS Backup ကို သုံးပြီး database, EBS, file system တွေကို schedule ချပြီး backup ယူနိုင်ပါတယ်။ Incident ဖြစ်လာတဲ့အချိန်မှာ backup ကနေ restore ပြန်လုပ်လို့ရပါတယ်။ ဒီ approach က cost effective ဖြစ်ပေမဲ့ restore process ကြာနိုင်သလို frequency အပေါ် မူတည်ပြီး data loss လည်း ဖြစ်နိုင်ပါတယ်။
နောက်တစ်ခုက replication-based design ပါ။ Data ကို real-time နဲ့ replicate လုပ်ထားပြီး standby system တစ်ခု ထားထားပါတယ်။ Region တစ်ခု outage ဖြစ်ရင် Route 53 ကို သုံးပြီး traffic ကို healthy region ဆီ redirect လုပ်နိုင်ပါတယ်။ ဒီ approach ကတော့ ကျွန်တော်တို့ system ကို ချက်ချင်း run နိုင်ပြီး data loss လည်း နည်းပါတယ်။ ဒါပေမယ့် infrastructure duplicate လုပ်ရတာကြောင့် cost effective တော့ မဖြစ်ပါဘူး။ ဒါကြောင့် system တိုင်းမှာ DR strategy တစ်ခုတည်းဆိုတာ မရှိပါဘူး။ Use case အပေါ် မူတည်ပြီး ရွေးရပါလိမ့်မယ်။ Internal tools တွေအတွက်တော့ backup-based approach က လုံလောက်နိုင်ပေမယ့် e-commerce, fintech system တွေလို zero downtime case တွေအတွက်တော့ replication-based design သုံးဖို့ လိုအပ်ပါတယ်။